
O que são tokens e como funcionam? (guia simples)
Se você já mexeu com ChatGPT, Gemini ou Claude, com certeza esbarrou na palavra token — no preço da API, no “limite de contexto” ou numa mensagem de erro.
Mas o que é, afinal, um token?
Vamos do zero, sem matemática.
O que é um token, afinal?
Um token é um pedaço de texto que a IA processa de uma vez.
Não é uma letra, e nem sempre é uma palavra inteira — na maioria das vezes é um pedaço de palavra.
Pense em como você quebraria uma palavra grande em sílabas.
Os modelos fazem algo parecido, só que do jeito deles: a palavra inteligência pode ser dividida em pedaços como intel + ig + ência.
Cada um desses pedaços é um token.

Palavras comuns e curtas (como “casa” ou “the”) costumam ser um único token.
Já palavras longas, raras ou com acento tendem a se quebrar em vários tokens.
Espaços e pontuação também contam.
Por que a IA não lê palavras nem letras?
Parece estranho não usar palavras inteiras.
A razão é eficiência e flexibilidade:
- Letra por letra seria lento demais. Um texto teria milhares de unidades, e o modelo gastaria energia demais para entender qualquer coisa.
- Palavra por palavra seria engessado. O modelo precisaria de uma lista gigante com todas as palavras que existem — e travaria diante de uma palavra nova, um nome próprio ou um erro de digitação.
O token é o meio-termo perfeito: pedaços de palavra permitem que o modelo monte praticamente qualquer texto a partir de um “alfabeto” de algumas dezenas de milhares de pedacinhos — incluindo palavras que ele nunca viu antes, juntando os pedaços certos.
Como os tokens funcionam por dentro
Aqui está o pulo do gato: o modelo não enxerga letras nem palavras — ele só enxerga números.
Cada token do “dicionário” do modelo (o chamado vocabulário) tem um número de identificação, um ID.
Quando você escreve uma frase, nos bastidores acontece o seguinte:
- Tokenização — sua frase é quebrada em tokens (os pedaços de palavra que vimos acima).
- Conversão em números — cada token vira o seu ID. A frase deixa de ser texto e passa a ser uma sequência de números: é só isso que o modelo recebe.
- Processamento — o modelo analisa essa sequência e calcula qual token tem mais chance de vir em seguida.
- Geração token a token — ele escolhe o próximo token, acrescenta à sequência e repete o processo, um token de cada vez, até formar a resposta inteira.
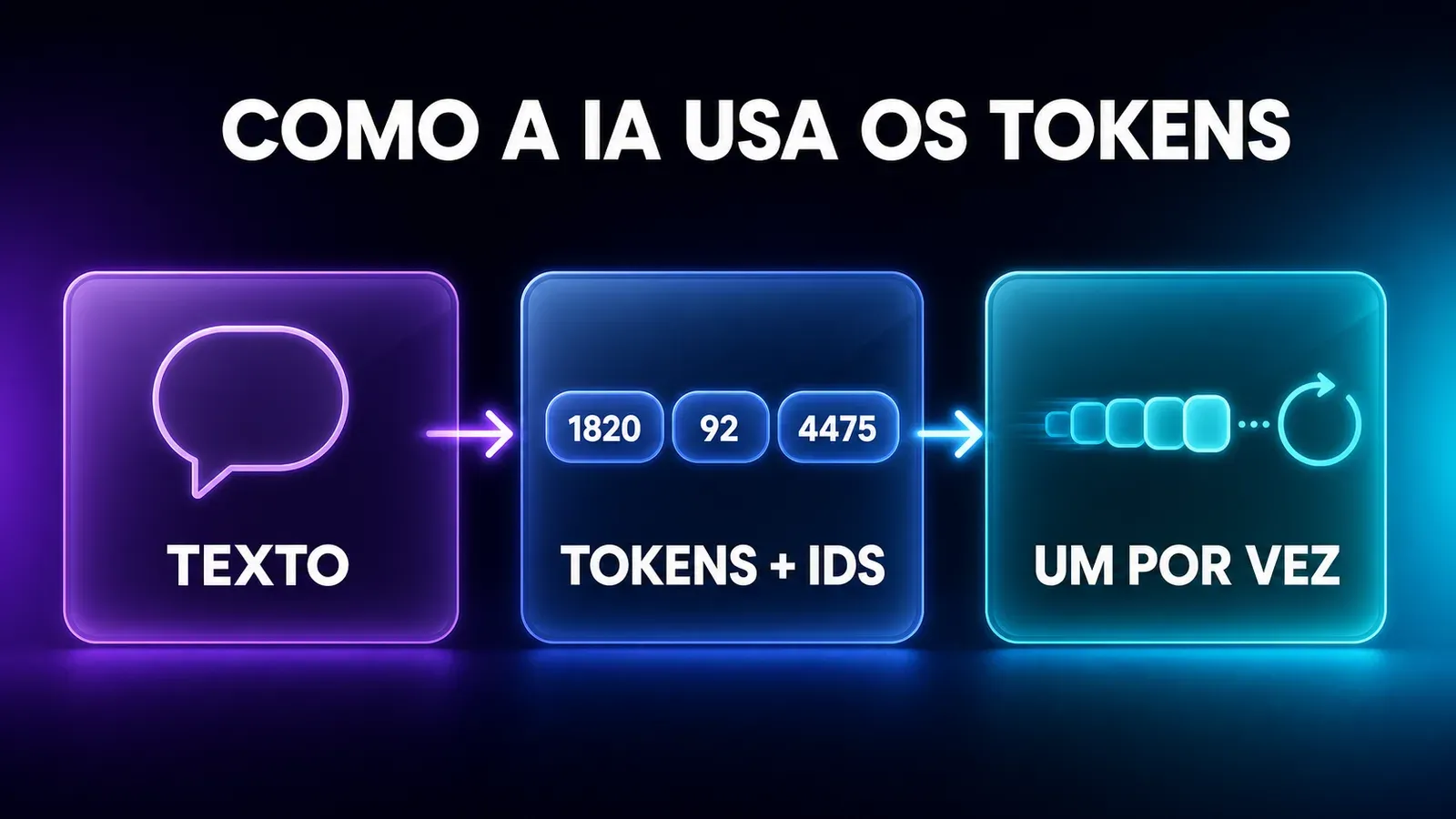
No fundo, conversar com uma IA é um vai-e-vem de tokens: você manda tokens, ela devolve tokens — e o texto que você lê na tela é só a “tradução” final desses números de volta para palavras.
Por que isso importa na prática
Como tudo na IA passa pelos tokens, eles acabam definindo três coisas que você sente no dia a dia:

1. Preço
As APIs de IA cobram por token — tanto pelo que você envia (input) quanto pelo que o modelo responde (output).
Textos mais longos = mais tokens = conta mais alta.
2. Limite de contexto (a “memória” da conversa)
Todo modelo tem um teto de tokens que consegue processar de uma vez — é a chamada janela de contexto.
Ela inclui tudo: sua pergunta, os arquivos que você colou, as instruções e a resposta.
Quando você estoura esse limite, a IA “esquece” o começo da conversa ou recusa o pedido.
3. Velocidade
Como o modelo gera a resposta um token de cada vez, quanto mais tokens na resposta, mais tempo ela demora para aparecer.
Respostas longas são literalmente mais lentas.
Conversas longas deixam a IA “burra”
Esse é o ponto que quase ninguém te conta — e é onde os tokens mais atrapalham no dia a dia.
A cada mensagem nova, a conversa não começa do zero.
O modelo recebe de novo todo o histórico (suas perguntas + todas as respostas anteriores), convertido em tokens, a cada vez.
Ou seja: quanto mais longa a conversa, mais tokens entram na janela de contexto a cada rodada.

E aí surgem dois problemas:
- A IA esquece o começo. Quando o histórico se aproxima do limite da janela, as primeiras mensagens são “espremidas” para fora — o modelo literalmente perde de vista o que foi combinado lá atrás.
- A atenção se dilui. Mesmo antes de estourar, uma conversa muito longa enche o contexto de texto. Com tanta coisa para considerar de uma vez, o modelo perde o fio, mistura informações e fica mais propenso a alucinar (inventar respostas com confiança).
Na prática, é como pedir para alguém lembrar, de uma só vez, de uma conversa de três horas: os detalhes começam a se embaralhar.
Não é que a IA ficou “burra” de verdade — é a janela de contexto abarrotada atrapalhando o raciocínio.
Quer entender melhor por que o modelo inventa respostas?
Veja O que é um LLM?, onde explicamos a alucinação a fundo.
Glossário rápido
- Token — pedaço de texto (geralmente parte de uma palavra) que o modelo lê e gera; é a unidade básica da IA.
- Tokenização — o processo de quebrar o texto em tokens antes de o modelo processá-lo.
- Vocabulário — o “dicionário” de todos os tokens que um modelo conhece, cada um com um número (ID).
- Janela de contexto — o máximo de tokens que um modelo consegue considerar de uma vez (pergunta + arquivos + resposta).
- BPE — Byte Pair Encoding, a técnica que define quais pedaços de texto viram tokens.
Resumo
- Um token é um pedaço de texto (em geral parte de uma palavra) — a unidade básica que a IA lê e gera.
- A IA usa tokens, e não letras ou palavras, por uma questão de eficiência e flexibilidade.
- Por dentro, o modelo só vê números: cada token vira um ID, e a resposta é gerada um token de cada vez.
- Como tudo passa pelos tokens, eles definem preço, limite de contexto e velocidade.
- Conversas longas enchem a janela de contexto: a IA esquece o começo, se confunde e alucina mais — comece um chat novo.
Próximo passo: sabendo o que são tokens, aprenda a escrever pedidos claros e eficazes em Como escrever seu primeiro prompt eficaz.