
O que é um LLM? Entenda de forma simples (sem matemática)
Se você já usou o ChatGPT, o Gemini ou o Claude, você já conversou com um LLM.
Mas o que é, afinal, essa sigla que está em todo lugar? Vamos do zero, sem fórmulas.
O que é um LLM, afinal?
LLM significa Large Language Model — em português, Grande Modelo de Linguagem.
É um tipo de inteligência artificial treinada para fazer uma coisa, e fazê-la muito bem: prever a próxima palavra de um texto.
A melhor analogia é o autocomplete do seu celular — aquele que sugere a próxima palavra quando você digita.
Um LLM é, essencialmente, um autocomplete absurdamente poderoso: em vez de ter visto as suas mensagens, ele “leu” uma fração gigantesca da internet, livros e código.
Quando você faz uma pergunta, ele não busca a resposta numa tabela.
Ele vai gerando, palavra por palavra, o texto mais provável que viria depois da sua pergunta.
É isso que cria a ilusão de uma conversa.
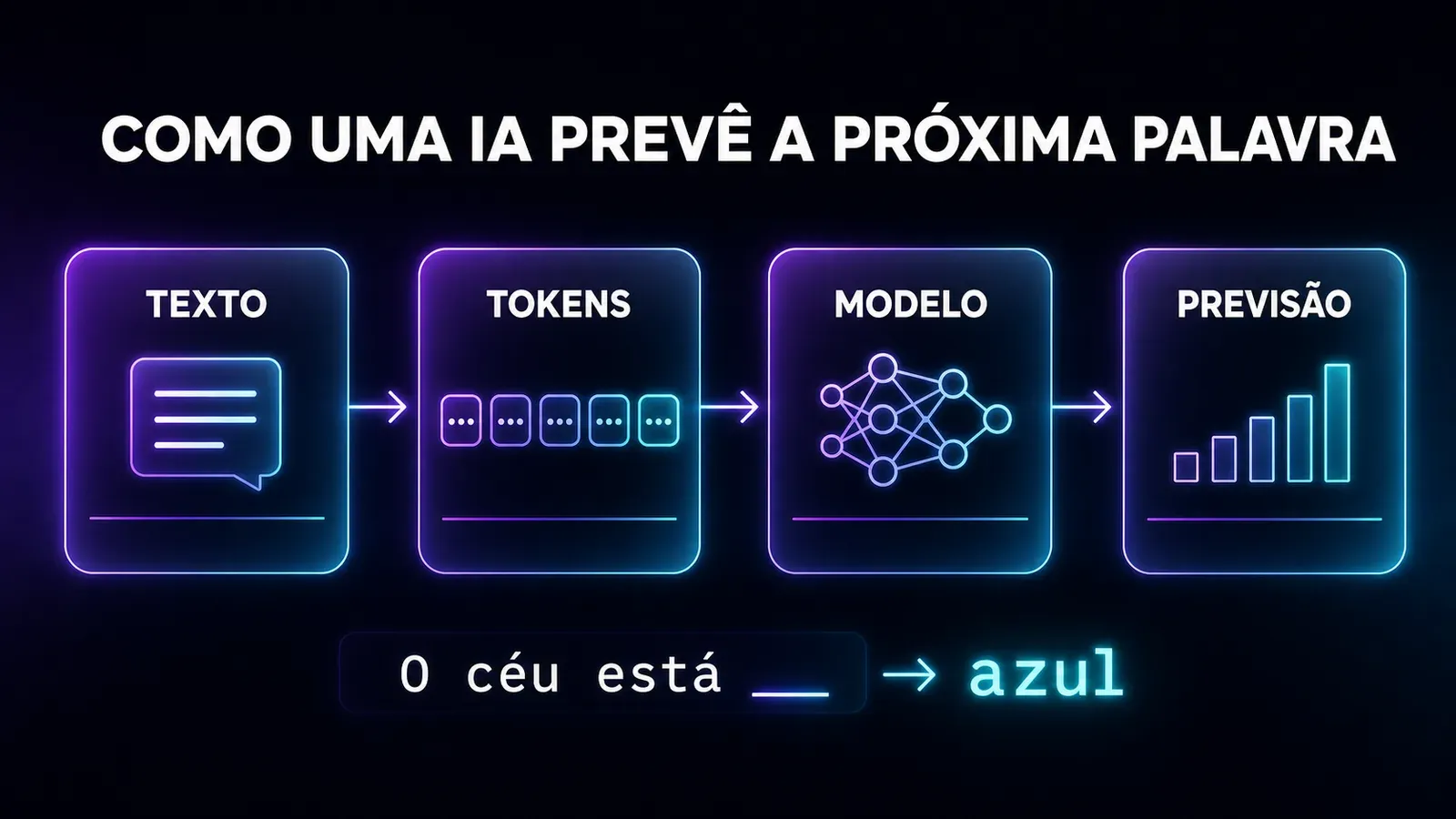
Como ele funciona (sem matemática)
O treinamento, no fundo, é um jogo repetido bilhões de vezes:
- Mostra-se ao modelo um trecho de texto com a última palavra escondida.
- Ele tenta adivinhar a palavra que falta.
- Compara-se com a palavra real e ajusta-se o modelo para errar menos da próxima vez.
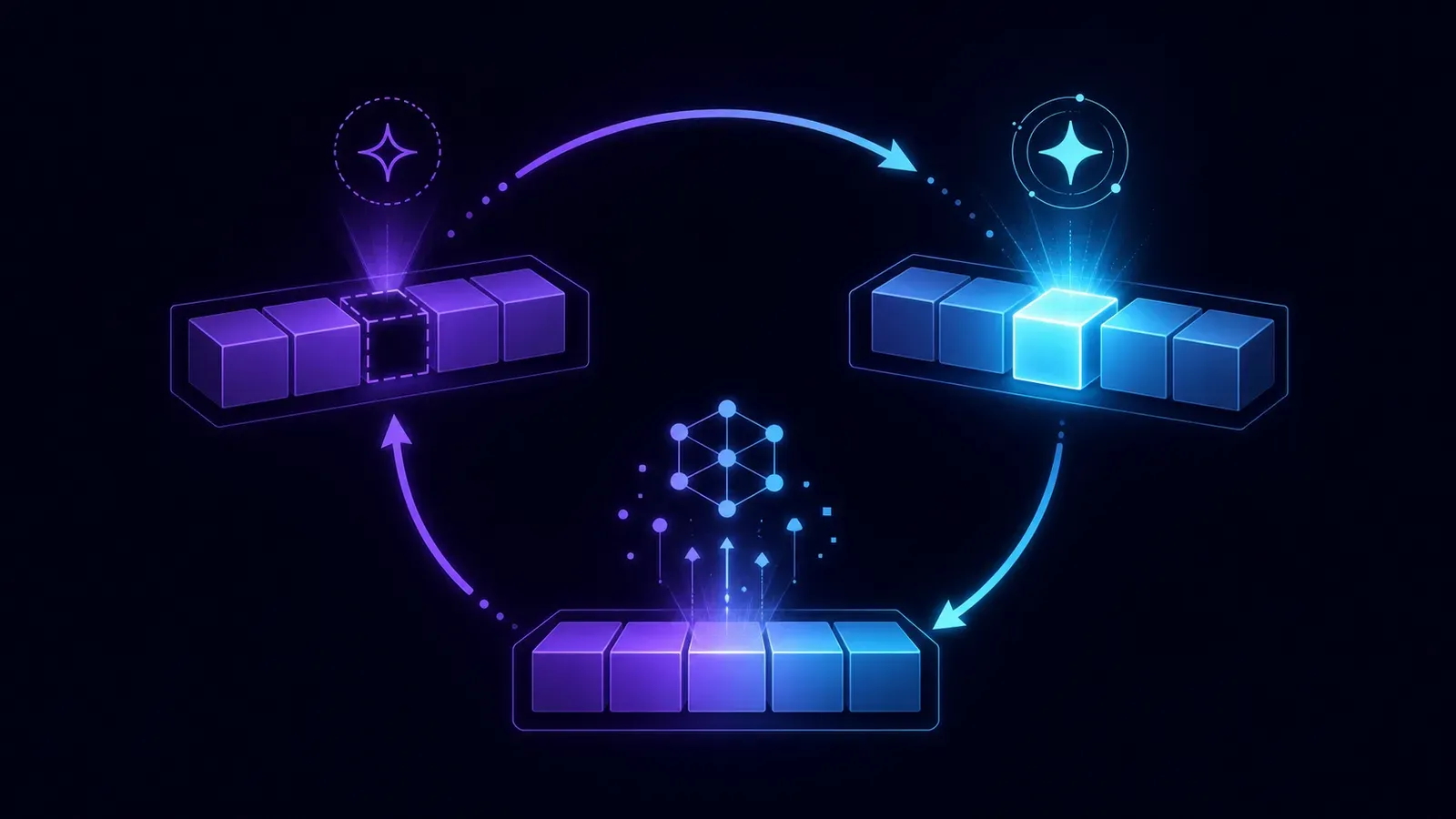
Repita isso por trilhões de exemplos e o modelo aprende padrões profundos da linguagem: gramática, fatos, estilos de escrita, raciocínios comuns — tudo isso só “tentando completar a frase”.
O que são “tokens”?
LLMs não leem letra por letra nem palavra por palavra exatamente — eles leem tokens, que são pedaços de texto.
A palavra “inteligência” pode virar 2 ou 3 tokens.
Isso importa na prática porque o preço e os limites de uma IA costumam ser contados em tokens.
Por que isso importa
Praticamente toda a onda de IA generativa que você vê — assistentes de escrita, geração de código, chatbots de atendimento, resumos automáticos — roda sobre LLMs.
Entender que por baixo é um “previsor de próxima palavra” muda como você usa a ferramenta:
- Você para de esperar uma “verdade absoluta” e passa a verificar o que importa.
- Você aprende que como você pergunta (o prompt) muda muito a resposta.
Por que ele às vezes inventa (alucina)
Esse é o ponto mais importante de todos.
Como o LLM gera o texto mais provável, e não o mais verdadeiro, ele pode produzir uma resposta que soa perfeita mas está errada — com nomes, datas ou fontes inventadas.
Isso se chama alucinação.

Não é “mentira” no sentido humano: o modelo não sabe que está errando.
Ele está fazendo exatamente o que foi treinado para fazer — escrever algo plausível. Por isso a regra de ouro:
Existe uma técnica que reduz bastante as alucinações: conectar o modelo a uma base de conhecimento confiável, em vez de confiar só na “memória” dele.
Mostramos como no tutorial RAG do zero: dê memória ao seu modelo de IA.
Glossário rápido
- LLM — Large Language Model; a IA que prevê a próxima palavra e está por trás do ChatGPT e similares.
- Token — pedaço de texto (parte de uma palavra) que o modelo processa; preço e limites são contados nele.
- Parâmetro — cada “ajuste interno” do modelo aprendido no treinamento; quanto mais, em geral, mais capaz.
- Prompt — a instrução/pergunta que você dá ao modelo.
- Alucinação — quando o modelo gera uma resposta plausível, porém falsa.
Resumo
- Um LLM é um autocomplete superpoderoso: prevê a próxima palavra com base em padrões aprendidos.
- Ele não consulta uma base de verdades — gera o texto mais provável, por isso pode alucinar.
- Saber disso te torna um usuário melhor: bom prompt + verificação dos fatos críticos.
Próximo passo: agora que você entende o que é um LLM, aprenda a conversar com ele do jeito certo em Como escrever seu primeiro prompt eficaz.