
What are tokens and how do they work? (a simple guide)
If you’ve used ChatGPT, Gemini or Claude, you’ve surely run into the word token — in API pricing, in the “context limit,” or in an error message.
But what exactly is a token? Let’s start from zero, no math.
What is a token, anyway?
A token is a chunk of text that the AI processes at once.
It isn’t a letter, and it isn’t always a whole word — most of the time it’s a piece of a word.
Think of how you’d break a long word into syllables.
Models do something similar, but in their own way: the word intelligence might be split into pieces like intel + lig + ence. Each of those pieces is a token.

Common, short words (like “house” or “the”) are usually a single token.
Long, rare or accented words tend to split into several tokens. Spaces and punctuation count too.
Why doesn’t AI read words or letters?
Not using whole words sounds odd. The reason is efficiency and flexibility:
- Letter by letter would be too slow. A text would have thousands of units, and the model would burn too much effort to understand anything.
- Word by word would be too rigid. The model would need a giant list of every word that exists — and it would choke on a new word, a proper name or a typo.
Tokens are the perfect middle ground: word-pieces let the model build almost any text from an “alphabet” of a few tens of thousands of little chunks — including words it has never seen, by stitching the right pieces together.
How tokens work under the hood
Here’s the key insight: the model doesn’t see letters or words — it only sees numbers.
Every token in the model’s “dictionary” (its vocabulary) has an identification number, an ID.
When you write a sentence, here’s what happens behind the scenes:
- Tokenization — your sentence is broken into tokens (the word-pieces we saw above).
- Conversion to numbers — each token becomes its ID. The sentence stops being text and turns into a sequence of numbers: that’s all the model receives.
- Processing — the model analyzes that sequence and computes which token is most likely to come next.
- Token-by-token generation — it picks the next token, appends it to the sequence and repeats the process, one token at a time, until the whole answer is formed.
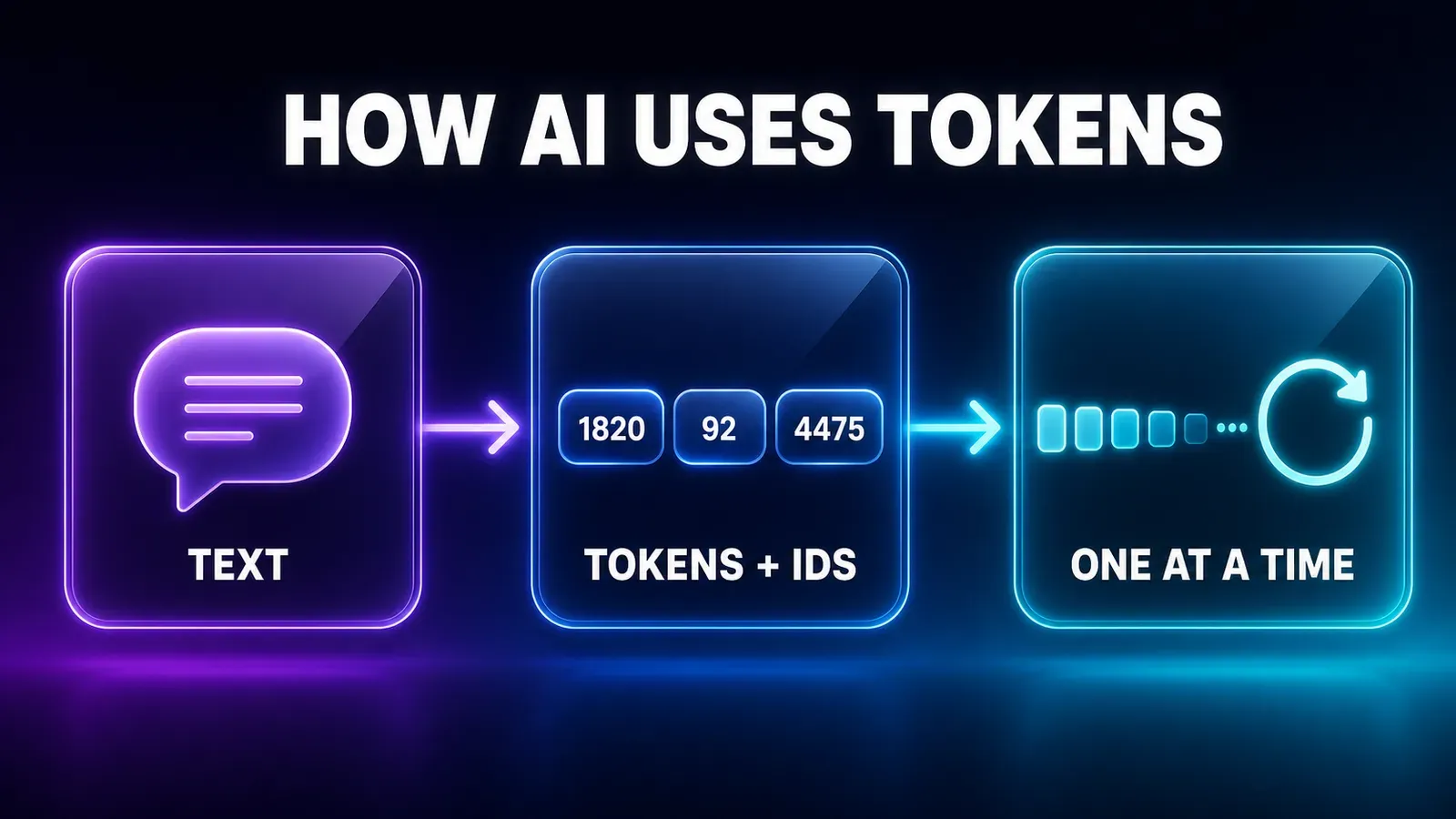
Deep down, talking to an AI is a back-and-forth of tokens: you send tokens, it returns tokens — and the text you read on screen is just the final “translation” of those numbers back into words.
Why it matters in practice
Since everything in AI flows through tokens, they end up defining three things you feel day to day:

1. Price
AI APIs charge per token — both for what you send (input) and for what the model replies (output).
Longer texts = more tokens = a bigger bill.
2. Context limit (the conversation’s “memory”)
Every model has a ceiling on the tokens it can process at once — the so-called context window.
It includes everything: your question, the files you pasted, the instructions and the answer.
When you blow past this limit, the AI “forgets” the start of the conversation or refuses the request.
3. Speed
Since the model generates the answer one token at a time, the more tokens in the response, the longer it takes to appear.
Long answers are literally slower.
Long conversations make the AI “dumber”
This is the part almost no one tells you — and it’s where tokens trip you up the most day to day.
With each new message, the conversation doesn’t start from scratch.
The model receives the entire history again (your questions + every previous answer), converted into tokens, every single time.
So the longer the conversation, the more tokens enter the context window each round.

Two problems follow:
- The AI forgets the beginning. As the history approaches the window’s limit, the earliest messages get “squeezed” out — the model literally loses sight of what was agreed earlier.
- Attention gets diluted. Even before overflowing, a very long conversation packs the context with text. With so much to weigh at once, the model loses the thread, mixes up information and becomes more likely to hallucinate (confidently make things up).
In practice, it’s like asking someone to recall a three-hour conversation all at once: the details start to blur.
It’s not that the AI got truly “dumb” — it’s the overcrowded context window getting in the way of its reasoning.
Want to understand why the model makes things up? See What is an LLM?, where we explain hallucination in depth.
Quick glossary
- Token — a chunk of text (usually part of a word) the model reads and generates; it’s the AI’s basic unit.
- Tokenization — the process of breaking text into tokens before the model processes it.
- Vocabulary — the “dictionary” of all the tokens a model knows, each with a number (ID).
- Context window — the maximum tokens a model can consider at once (question + files + answer).
- BPE — Byte Pair Encoding, the technique that defines which chunks of text become tokens.
Summary
- A token is a chunk of text (usually part of a word) — the basic unit the AI reads and generates.
- AI uses tokens, not letters or words, for efficiency and flexibility.
- Under the hood, the model only sees numbers: each token becomes an ID, and the answer is generated one token at a time.
- Since everything flows through tokens, they define price, context limit and speed.
- Long conversations fill the context window: the AI forgets the start, gets confused and hallucinates more — start a new chat.
Next step: now that you know what tokens are, learn to write clear, effective requests in How to write your first effective prompt.