
What is an LLM? A simple explanation (no math)
If you’ve ever used ChatGPT, Gemini or Claude, you’ve already talked to an LLM.
But what is this acronym that’s everywhere? Let’s start from zero, no formulas.
What is an LLM, anyway?
LLM stands for Large Language Model.
It’s a type of artificial intelligence trained to do one thing, and do it extremely well: predict the next word in a piece of text.
The best analogy is your phone’s autocomplete — the one that suggests the next word as you type.
An LLM is essentially an absurdly powerful autocomplete: instead of having seen your messages, it “read” a huge fraction of the internet, books and code.
When you ask a question, it doesn’t look the answer up in a table.
It generates, word by word, the most likely text that would come after your question. That’s what creates the illusion of a conversation.
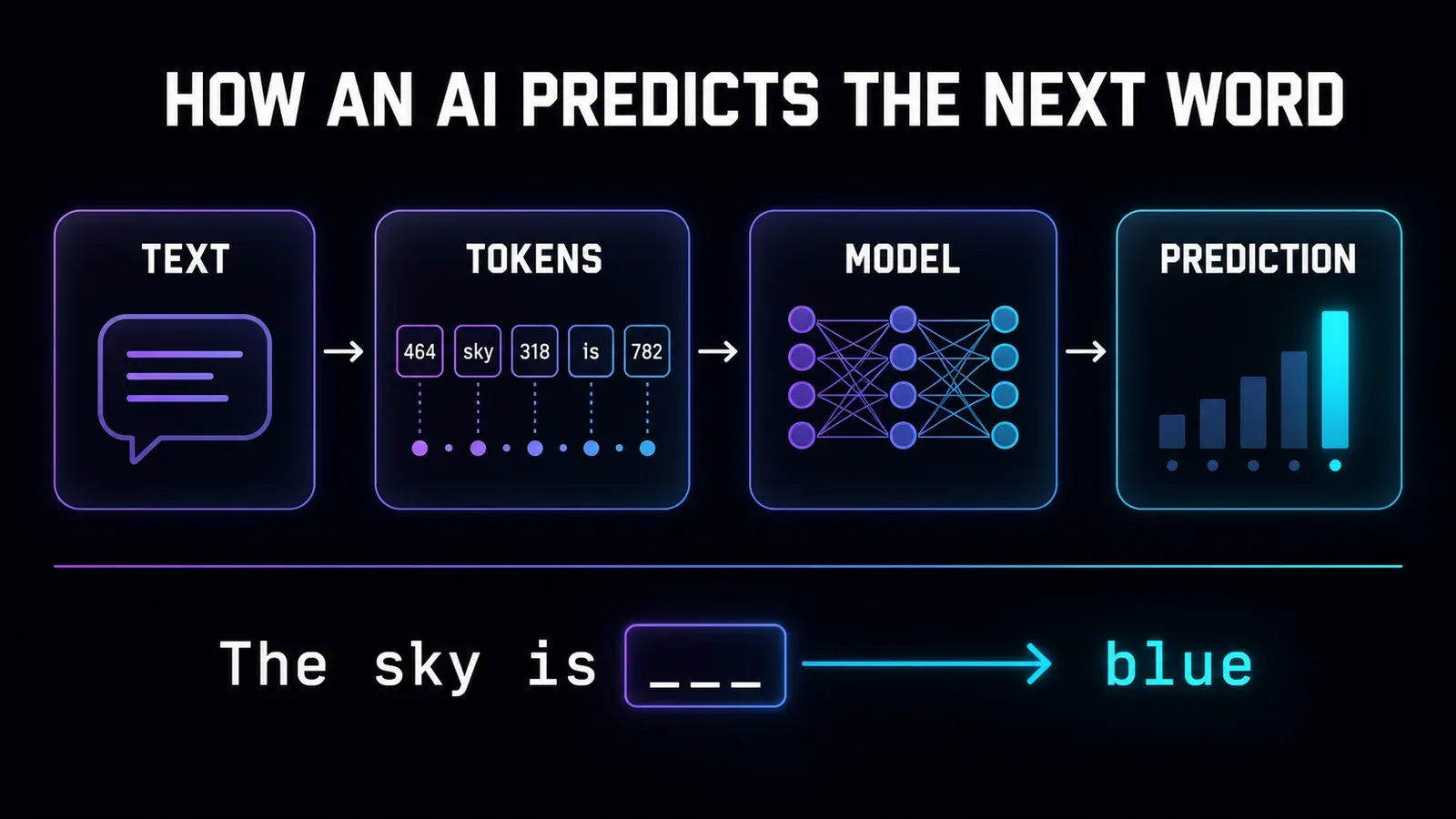
How it works (no math)
Training is, at its core, a game repeated billions of times:
- The model is shown a passage of text with the last word hidden.
- It tries to guess the missing word.
- The guess is compared to the real word, and the model is adjusted to be wrong less often next time.
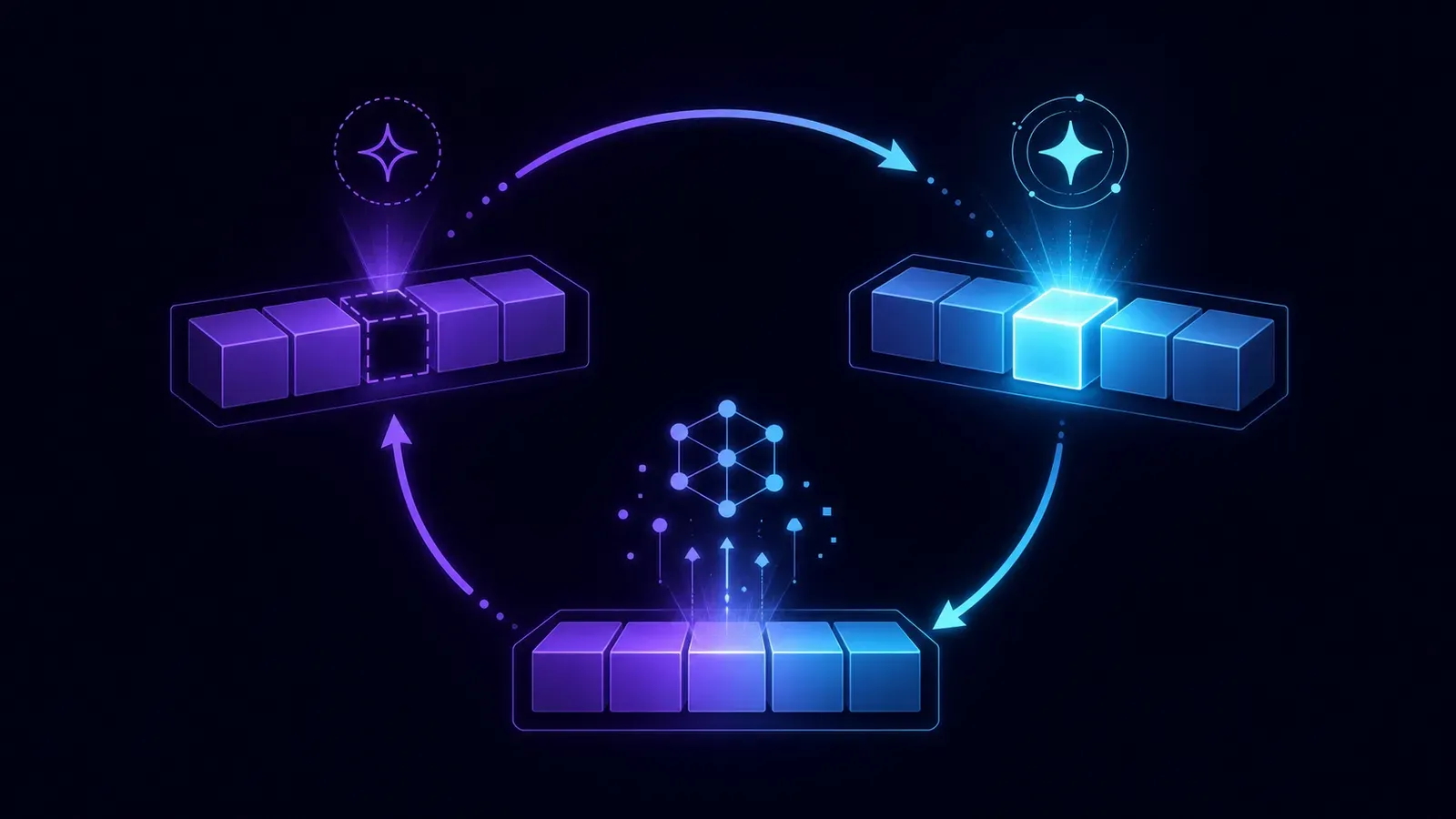
Repeat this across trillions of examples and the model learns deep patterns of language: grammar, facts, writing styles, common reasoning — all just by “trying to finish the sentence.”
What are “tokens”?
LLMs don’t read letter by letter or exactly word by word — they read tokens, which are chunks of text.
The word “intelligence” might become 2 or 3 tokens.
This matters in practice because the price and limits of an AI are usually counted in tokens.
Why it matters
Almost the entire wave of generative AI you see — writing assistants, code generation, support chatbots, automatic summaries — runs on LLMs.
Understanding that, underneath, it’s a “next-word predictor” changes how you use the tool:
- You stop expecting “absolute truth” and start verifying what matters.
- You learn that how you ask (the prompt) changes the answer a lot.
Why it sometimes makes things up (hallucinates)
This is the single most important point.
Because an LLM generates the most likely text, not the most truthful, it can produce an answer that sounds perfect but is wrong — with made-up names, dates or sources. This is called a hallucination.

It’s not “lying” in the human sense: the model doesn’t know it’s wrong.
It’s doing exactly what it was trained to do — write something plausible. Hence the golden rule:
There’s a technique that cuts hallucinations significantly: connecting the model to a trusted knowledge base instead of relying only on its “memory.”
We show how in the tutorial RAG from scratch: give your AI model memory.
Quick glossary
- LLM — Large Language Model; the AI that predicts the next word and powers ChatGPT and similar tools.
- Token — a chunk of text (part of a word) the model processes; price and limits are counted in tokens.
- Parameter — each internal “adjustment” the model learns during training; more usually means more capable.
- Prompt — the instruction/question you give the model.
- Hallucination — when the model generates a plausible but false answer.
Summary
- An LLM is a super-powered autocomplete: it predicts the next word based on learned patterns.
- It doesn’t look up a database of truths — it generates the most likely text, which is why it can hallucinate.
- Knowing this makes you a better user: good prompt + verifying critical facts.
Next step: now that you understand what an LLM is, learn how to talk to it the right way in How to write your first effective prompt.